The alignment of Large Language Models (LLMs) and brain activity provides a powerful framework to advance our understanding of cognitive neuroscience and artificial intelligence. MindTransformer zooms into one of the fundamental units of LLMs—the transformer block—to provide the first systematic computational neuroanatomy of its internal operations and human brain activity.
Analyzing 21 state-of-the-art LLMs (270M–123B parameters) across five major families, we reveal a universal intra-block hierarchy: early attention states align with sensory cortices, while Feedforward Network (FFN) states align with higher-order association areas. Over 90% and 96% of brain voxels in language and sensory regions are better explained by previously unexplored intermediate computations than by the commonly used hidden states.
Furthermore, we identify that Rotary Positional Embeddings (RoPE) are the specific mathematical engine driving alignment in the human auditory cortex—per-head queries with RoPE best explain 74% of auditory cortex voxels versus 8% without, systematically improving alignment along both ventral and dorsal auditory pathways. Building on these insights, MindTransformer achieves correlation improvements of 0.111 in primary auditory cortex—gains that exceed those from scaling LLMs by 456×.
Framework
Dissecting the Transformer Block
We decompose each transformer block into 13 distinct intermediate states and map each to human brain activity.
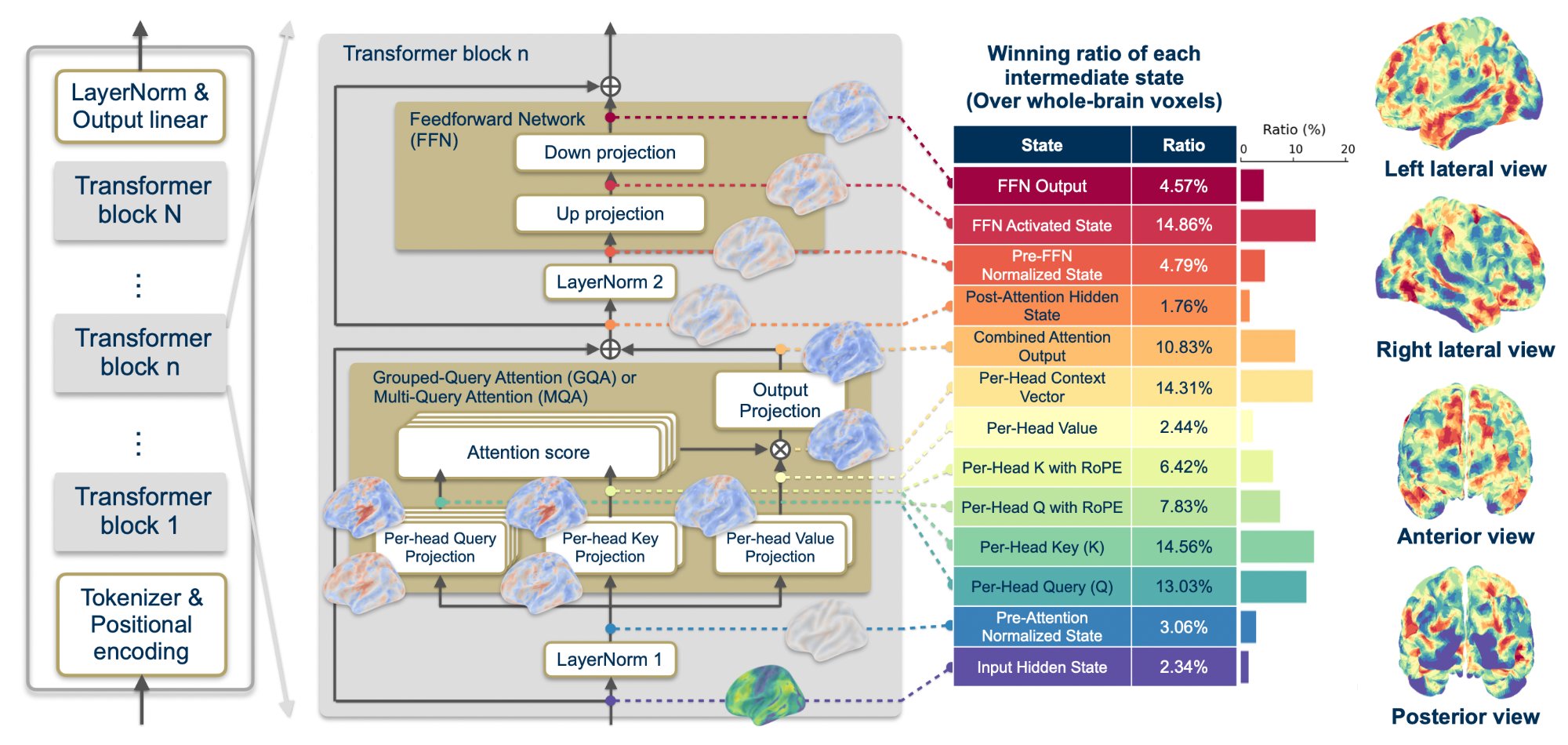
Figure 1 · Overview of the MindTransformer Framework
We extract 13 fine-grained intermediate states from each transformer block (left) and map them to human brain activity via voxel-wise encoding models. The winning ratio analysis (center) reveals that no single standard representation dominates—diverse states contribute across the brain. Brain plots (right) show the best-performing state for each voxel, revealing a double dissociation: FFN Activated States and Per-Head Context Vectors dominate in semantic processing regions (Language Network), while RoPE-enhanced attention states dominate in sensory cortices (Auditory Cortex).
Highlights
Key Discoveries
Three principal contributions from our computational neuroanatomy analysis.
+31%
Auditory Cortex Gain
MindTransformer achieves 0.467 correlation in Heschl's Gyrus—a 31.0% improvement over baselines that surpasses the gains from scaling model size by 456× (270M → 123B parameters). The improvement is 29.2% random-adjusted and 46.0% GloVe-adjusted.
RoPE
Auditory Stream Engine
Rotary Positional Embeddings are the critical component: per-head queries with RoPE explain 73.88% of auditory cortex voxels versus just 7.82% without—a nearly tenfold increase. This effect delineates both the ventral and dorsal auditory processing streams.
5 Families
Universal Hierarchy
The intra-block hierarchy is universal across Llama, Mistral, Qwen, Gemma, and GPT: early attention states → sensory cortices, FFN states → association areas. This parallels the brain's own processing hierarchy at a within-block level of granularity.
Finding 1
Universal Intra-Block Hierarchy
The computational depth within a single transformer block mirrors the brain's cortical hierarchy.
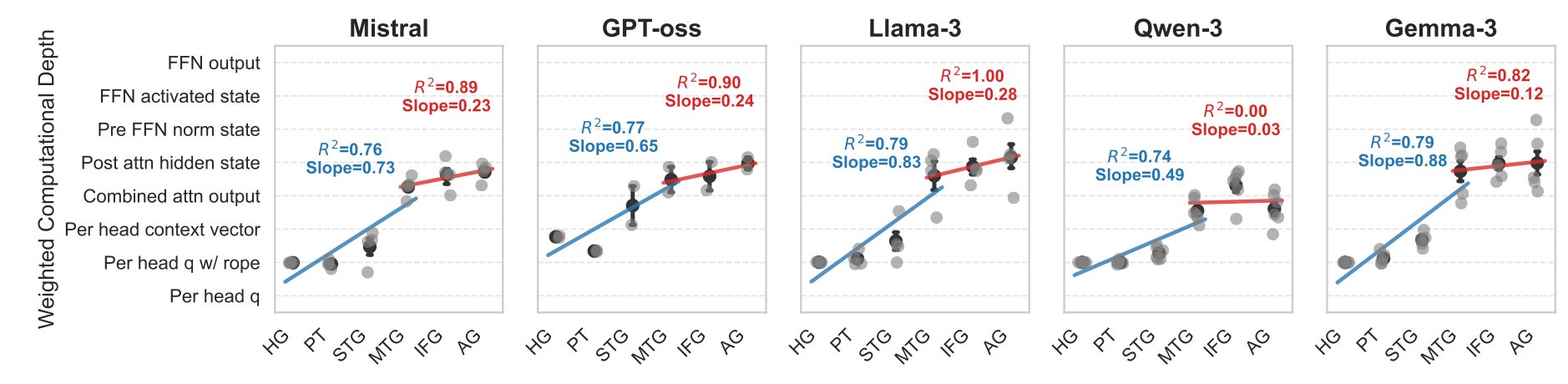
Figure 2 · Weighted Computational Depth vs. Cortical Hierarchy
We quantify the topological alignment between the transformer's internal processing depth (y-axis) and the brain's cortical hierarchy (x-axis) across five LLM families. Two functional segments emerge: the auditory stream (HG → MTG) shows a steep slope where ascending cortical levels correspond to deeper intra-block computations, while the language network (MTG → AG) shows a plateau where alignment stabilizes at the block's later stages. High R² values across most families confirm this is a universal property of transformer architectures.
Finding 2
The Neurobiological Role of RoPE
Rotary Positional Embeddings delineate the brain's canonical ventral and dorsal auditory streams.
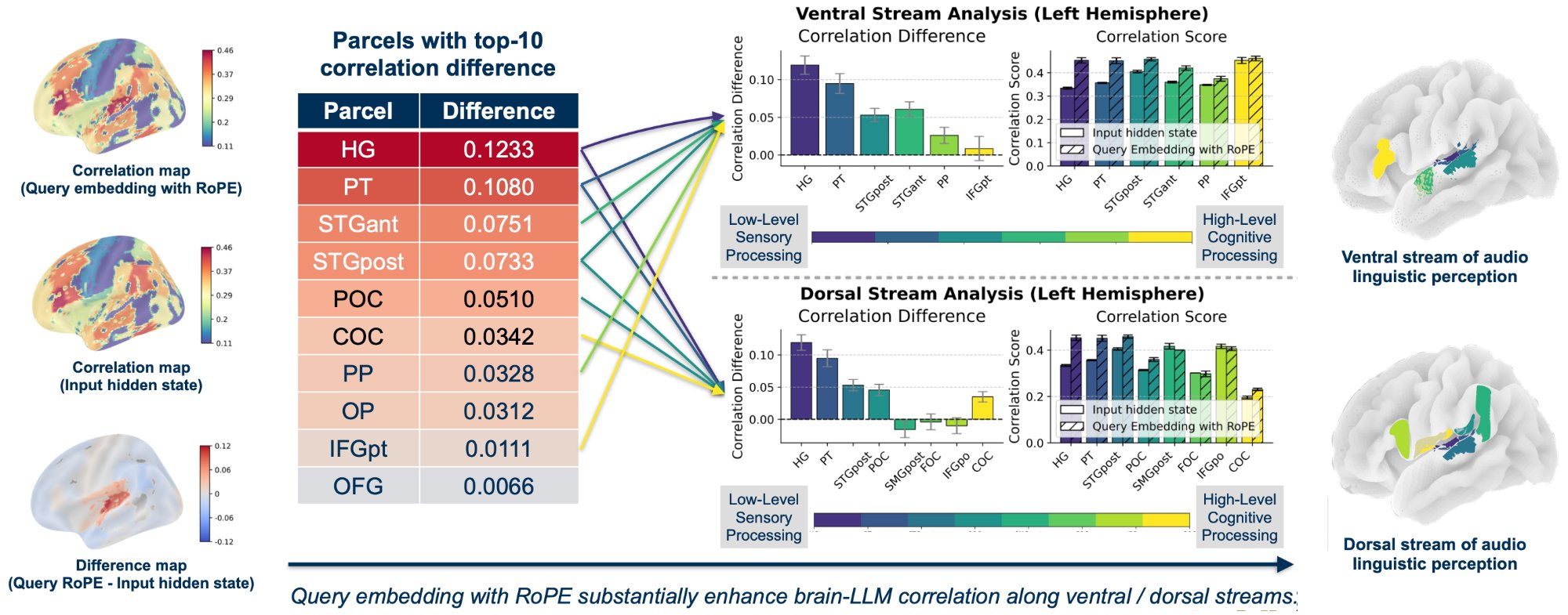
Figure 3 · RoPE Delineates the Brain's Auditory Streams
Comparing per-head query with RoPE vs. input hidden states, the difference map (left) reveals strong improvement concentrated around the Sylvian fissure. The top-10 parcels with highest correlation difference (center) strikingly delineate the brain's canonical ventral and dorsal streams for auditory language processing. The largest improvement is in primary auditory cortex (Heschl's Gyrus, Δ=0.1233), cascading along both anatomical streams to the Planum Temporale and Superior Temporal Gyrus. This provides the first neurobiological validation of RoPE's functional role and the first strong evidence of LLM-brain alignment in low-level sensory processing regions.
Finding 3
Efficiency vs. Scale
Computational neuroanatomy insights outperform massive model scaling.
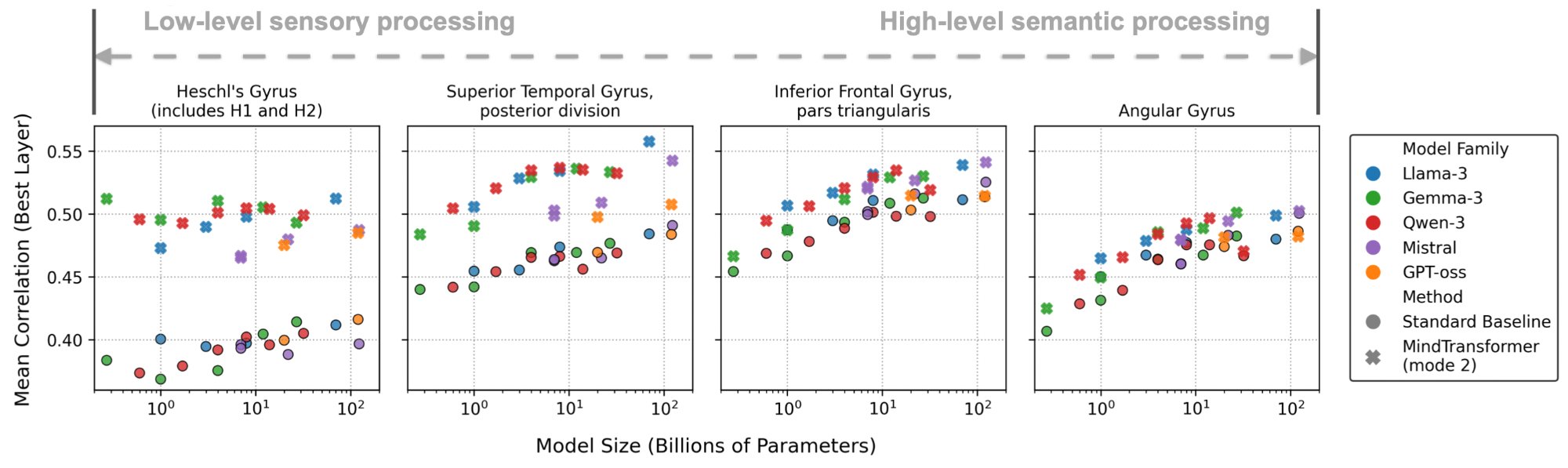
Figure 4 · Beating the Scaling Laws
We compare MindTransformer (Mode 2, ✕ markers) against standard baselines (● markers) across models from 270M to 123B parameters. In low-level sensory regions like Heschl's Gyrus (leftmost panel), MindTransformer's improvement is substantially larger than gains from 456× model scaling. Moving toward high-level semantic regions (rightward panels), the gap narrows as standard baselines already perform well. This demonstrates that understanding the internal computational neuroanatomy of transformers yields greater efficiency than simply increasing model size—particularly in sensory regions where traditional approaches have struggled.
Scope
Comprehensive Analysis
Validated across 21 models spanning 5 architectural families, from 270M to 123B parameters.
Family
Model Variants (Parameters)
Layers
Llama-3
1B, 3B, 8B, 70B
16 – 80
Qwen-3
0.6B, 1.7B, 4B, 8B, 14B, 32B
28 – 64
Mistral
7B (v0.2/v0.3), Small (22B), Large (123B)
32 – 88
GPT-oss
20B, 120B
24 – 36
Gemma-3
270M, 1B, 4B, 12B, 27B
18 – 62
Reference
Citation
@inproceedings{chen2026mindtransformer,
title = {The Mind's Transformer: Computational Neuroanatomy
of LLM-Brain Alignment},
author = {Chen, Cheng-Yeh and Sivakumar, Raghupathy},
booktitle = {International Conference on Learning
Representations (ICLR)},
year = {2026}
}